ChatWith+ ChatGPT Plugins
ChatWithPDF
Is a ChatGPT plugin that allows users to query against small or large PDF documents directly in ChatGPT.
Installation
ChatWithPDF is a ChatGPT plugin. To install ChatWithPDF, simply add it in the 'Plugin Store' once you select Model: GPT-4 -> Plugins -> Plugin Store in the ChatGPT UI (if you are a ChatGPT Pro user)

Usage
To use ChatWithPDF, simply provide a publically accessible PDF URL to be loaded and processed. You can use a publically accessible Google Drive link to a PDF document(no photocopies) or upload your documents to a service like tmpfiles.org and use that while chatting with ChatWithPDF. The plugin will then fetch relevant information from the PDF file and return the most suitable matches according to your search input.
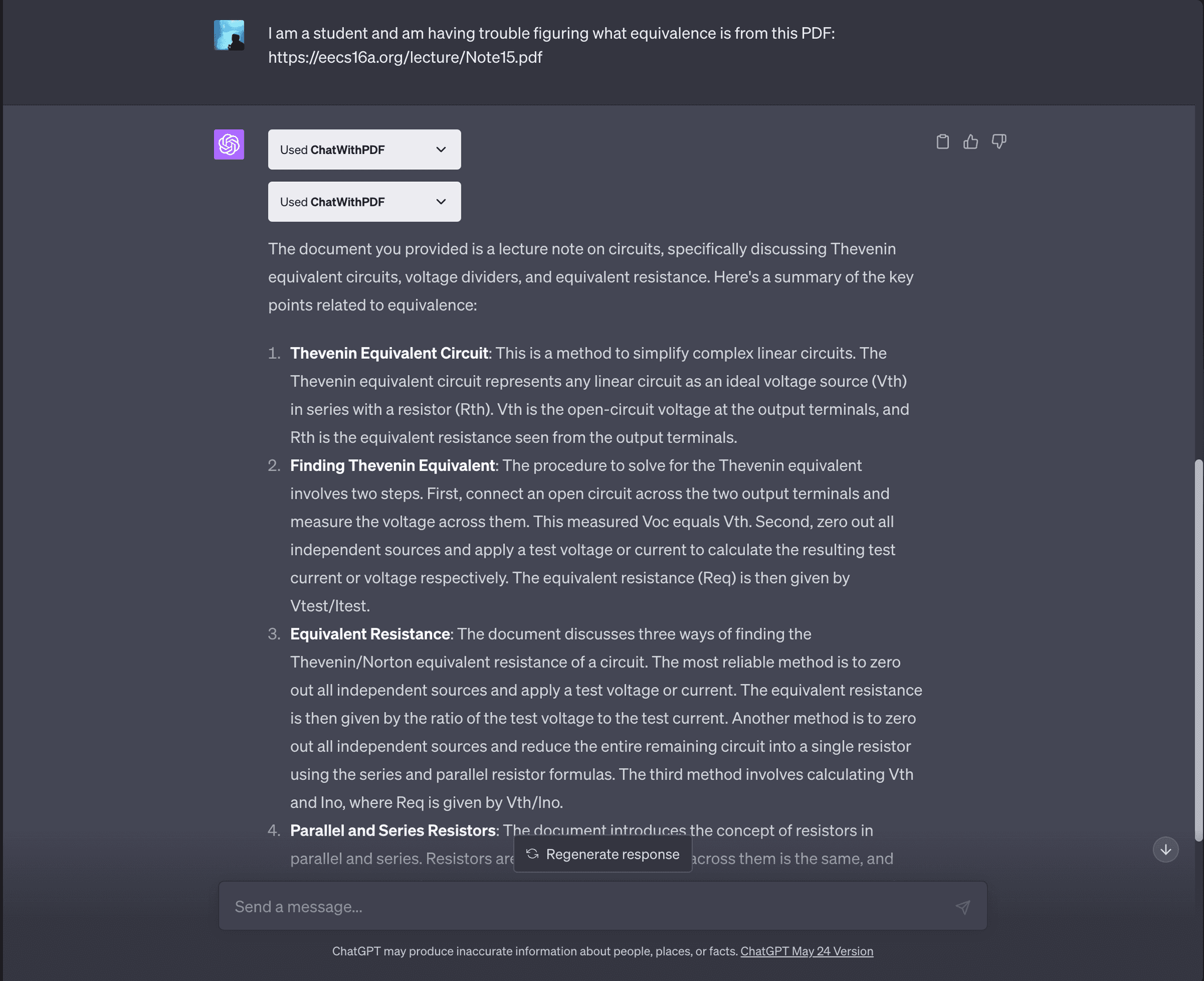
Example ChatGPT conversation link: https://chat.openai.com/share/1ae4921a-bf5e-4baa-a4af-32514dc70c46
- You: "I am a student and am having trouble figuring what equivalence is from this PDF: https://eecs16a.org/lecture/Note15.pdf"
- ChatGPT: "loading"
- ChatGPT: "The document you provided is a lecture note on circuits, specifically discussing Thevenin equivalent circuits, voltage dividers, and equivalent resistance. Here's a summary of the key points related to equivalence"...
Overview
This ChatGPT plugin offers a convenient way to process and semantically search PDF documents based on your queries. By providing a temporary PDF URL, the plugin fetches relevant information from the PDF file and returns the most suitable matches according to your search input.
Features
ChatWithPDF offers a variety of features to help you get the most out of your PDF documents. These include:
- Search PDFs directly in ChatGPT
- Search PDFs of any size
- Search PDFs of any language
- Search PDFs of any topic
- Search PDFs of any length
- Search PDFs of any quality
Privacy
ChatWithPDF does not intentionally store any data permanently. All PDFs are embedded and immediately wiped. Embeddings are stored with ChromaDB on the same deployment server and are wiped with each new deployment. Typically embeddings are manually purged due to limiatations in our vector database every 12-24 hours due to size+memory constraints. In the future all embeddings will be deleted 1hr after the user requests them. If someone has your link they can also fetch embeddings from it since it is already cached in our vector database, however users cannot figure out what other users have searched or embedded.
How it works
Users provide a publically accessible PDF URL to be loaded and processed(should be able to be accessed from Incognito mode for instance). The plugin downloads and processes the PDF document, extracting relevant information. User queries are matched with the processed information from the PDF. The most relevant matches are returned and displayed to the user.